目录
CUDA
功能使用
-
kernel的启动参数
Kernel<<<Dg,Db, Ns, S>>>(param list);
-
参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
-
参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。 一个block中共有Db.xDb.yDb.z个thread。计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
-
参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。不需要动态分配时该值为0或省略不写。
-
参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
-
-
thread计算
c++// grid 1, block 1 int threadId = blockIdx.x *blockDim.x + threadIdx.x; // grid 1, block 2 int threadId = blockIdx.x * blockDim.x * blockDim.y+ threadIdx.y * blockDim.x + threadIdx.x; // grid 1, block 3 int threadId = blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x; // grid 2, block 1 int blockId = blockIdx.y * gridDim.x + blockIdx.x; int threadId = blockId * blockDim.x + threadIdx.x; // grid 2, block 2 int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; // grid 2, block 3 int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x; // grid 3, block 1 int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * blockDim.x + threadIdx.x; // grid 3, block 2 int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; // grid 3, block 3 int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x; -
kernel传值和传指针
传指针只能传GPU地址,传值可以直接传CPU上的变量,编译器会把标量变量放到寄存器里面
-
Global memory合并访问Coalesced
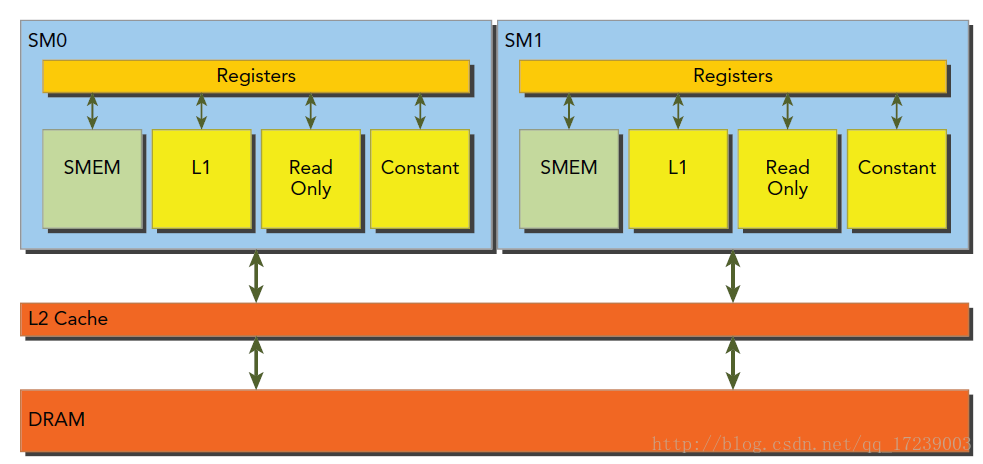
全局内存的访问应该满足coalesced,除了连续之外,而且它开始的地址,必须是每个 thread 所存取的大小的 16 倍。例如,如果每个thread 都读取 32 bits 的数据,那么第一个 thread 读取的地址,必须是 16*4 = 64 bytes 的倍数:
-
如果有一部份的 thread 没有读取内存,并不会影响到其它的 thread 执行 coalesced 的存取
-
每个 thread 一次读取的内存数据量,可以是 32 bits、64 bits、或 128 bits。不过,32 bits 的效率是最好的。64 bits 的效率会稍差,而一次读取 128 bits 的效率则比一次读取 32 bits 要显著来得低(但仍比 non-coalesced 的存取要好),比如下面的代码就不是,因为一次读了12 bytes
c++struct vec3d { float x, y, z; }; ... __global__ void func(struct vec3d* data, float* output) { output[tid] = data[tid].x * data[tid].x + data[tid].y * data[tid].y + data[tid].z * data[tid].z; }
对于非coalesced 的读取,可以:
- 使用
__align(n)__补齐 - 调整数据结构,比如
vec3d拆分成三个float数组 - 先用连续的方式,把数据从 global memory 读到 shared memory
-
-
stream相关
-
多个kernel之间如果是有依赖关系的,要放在同一个stream上,位于同一个stream上的kernel是串行执行的
-
没有依赖关系的(除kernel以外,包括
cudaMemcpy,cudaMemset之类)可以放到不同的stream上,可以实现kernel间的并行 -
如果kernel之间有比较复杂的依赖关系,或者是kernel之间相互运行次序固定但需要运行很多次时,可以考虑使用
cudaGraph,cudaGraph不仅可以显式的构造多个kernel(也包括一些memcpy之类的操作)的依赖关系,还可以通过运行上的合理安排减少每个kernel启动的overhead -
cudaGragh 相关使用,可以用stream自动capture也可以手动建图,相关资料:
-
https://github.com/NVIDIA/cuda-samples/tree/master/Samples/3_CUDA_Features/simpleCudaGraphs
-
https://developer.nvidia.com/blog/employing-cuda-graphs-in-a-dynamic-environment/
-
如果在capture的时候有多个stream,开始需要join,否则报904 (The capture sequence contains a fork that was not joined to the primary stream),具体操作如下
c++CHECK(cudaStreamBeginCapture(stream1, cudaStreamCaptureModeGlobal)); CHECK(cudaEventRecord(forkStreamEvent, stream1)); CHECK(cudaStreamWaitEvent(stream2, forkStreamEvent, 0)); CHECK(cudaStreamWaitEvent(stream3, forkStreamEvent, 0)); -
capture的过程中不能使用任何的同步操作,包括
cudaStreamSynchronize()和cudaDeviceSynchronize()等,否则会报901(The current capture sequence on the stream has been invalidated due to a previous error)或者900(The operation is not permitted when the stream is capturing) -
capture过程中不能调用一部分的API,比如分配设备内存,否则会报901
c++/* During stream capture (see ::cudaStreamBeginCapture), some actions, such as a call to ::cudaMalloc, may be unsafe. In the case of ::cudaMalloc, the operation is not enqueued asynchronously to a stream, and is not observed by stream capture. Therefore, if the sequence of operations captured via ::cudaStreamBeginCapture depended on the allocation being replayed whenever the graph is launched, the captured graph would be invalid. Therefore, stream capture places restrictions on API calls that can be made within or concurrently to a ::cudaStreamBeginCapture-::cudaStreamEndCapture sequence. This behavior can be controlled via this API and flags to ::cudaStreamBeginCapture./* -
cudaGragh和TensorRT一起使用时,注意应该在调用
setOptimizationProfileAsync()后先调用一次enqueueV2()在开始capture,否则可能由于资源的分配导致capture失败。不清楚enqueueV3()有没有这个问题。c++/* Note: Calling enqueueV2() with a stream in CUDA graph capture mode has a known issue. If dynamic shapes are used, the first enqueueV2() call after a setInputShapeBinding() call will cause failure in stream capture due to resource allocation.Please call enqueueV2() once before capturing the graph.*/
-
-
-
tensorcore
- WMMA:用tensorcore做矩阵乘加
- 自己写的CUDA矩阵乘法能优化到多快? - nicholaswilde的回答 - 知乎 https://www.zhihu.com/question/41060378/answer/2645323107
- https://github.com/NVIDIA/cuda-samples/blob/master/Samples/3_CUDA_Features/cudaTensorCoreGemm
- WMMA:用tensorcore做矩阵乘加
-
协作组 Cooperative Groups
-
nvrtc 运行时编译
读取一个文本文件(包含代码),运行时编译为可执行的kernel,用例:NVRTC (nvidia.com)
主要API包括:
nvrtcCreateProgram- 创建nvrtcProgramnvrtcCompileProgram- 编译nvrtcProgramnvrtcAddNameExpression- 添加函数/变量的名字,用于定位函数/变量(nvrtcAddNameExpression notes the given name expression denoting the address of a global function or device/constant variable. The identical name expression string must be provided on a subsequent call to nvrtcGetLoweredName to extract the lowered name.)如果kernel是模板的话,在这里需要加入模板参数,比如kernel<int>,kernel<float>等,就可以实例化出不同版本的kernel以供后续的执行nvrtcGetLoweredName- 获取编译后的函数/变量名字,用于后续后续函数/变量的handle (extracts the lowered (mangled) name for a global function or device/constant variable, and updates *lowered_name to point to it. The identical name expression must have been previously provided to nvrtcAddNameExpression.)nvrtcGetPTX/nvrtcGetPTXSize- 从program中获取PTX codecuModuleLoadData/ cuModuleLoadDataEx - 从PTX或者fatbin中加载CUmodulecuModuleGetFunction- 从CUmodule中获取CUfunction,注意kernel的名字是nvrtcGetLoweredName拿到的
nvrtc相关的资料:
- NVRTC (nvidia.com) 官方文档
- New Compiler Features in CUDA 8 | NVIDIA Technical Blog Runtime Compilation And Dynamic Parallelism / Template Host Code
demangle:C/C++语言在编译以后,函数的名字会被编译器修改,改成编译器内部的名字,这个名字会在链接的时候用到。将C++源程序标识符(original C++ source identifier)转换成C++ ABI标识符(C++ ABI identifier)的过程称为mangle;相反的过程称为demangle。CUDA采用C++相同的标准,因此可以用C++的demangle工具来解析函数的签名
-
abi::__cxa_demangle -
C++filt
-
nv_decode.h 中的
__cu_demangle为CUDA官方提供的demangle接口c++#include <stdio.h> #include <stdlib.h> #include "nv_decode.h" int main() { int status; const char *real_mangled_name="_ZN8clstmp01I5cls01E13clstmp01_mf01Ev"; const char *fake_mangled_name="B@d_iDentiFier"; char* realname = __cu_demangle(fake_mangled_name, 0, 0, &status); printf("fake_mangled_name:\t result => %s\t status => %d\n", realname, status); free(realname); size_t size = sizeof(char)*1000; realname = (char*)malloc(size); __cu_demangle(real_mangled_name, realname, &size, &status); printf("real_mangled_name:\t result => %s\t status => %d\n", realname, status); free(realname); return 0; }输出
fake_mangled_name: result => (null) status => -2 real_mangled_name: result => clstmp01<cls01>::clstmp01_mf01() status => 0
-
可变参数模板
- C++11 in CUDA: Variadic Templates | NVIDIA Technical Blog
- New Compiler Features in CUDA 8 | NVIDIA Technical Blog Improved nvstd::function (Polymorphic Functional Wrapper)
编译/优化/底层
-
指令级原语调整(CUDA编程第七章: 调整指令级原语_cuda fmad_Janus_V的博客-CSDN博客):原语通常由若干条指令组成,用来实现某个特定的操作。通过一段不可分割的或不可中断的程序实现其功能。计算中一种常见的模式:x * y + z 这种乘法后紧跟加法的算术模式被称为乘法加,或者MAD。一个简单的编译器会把一个MAD指令转化成两个算术指令:先进行乘法运算紧接着进行加法运算。因为这种模式很常见,所以现代运算结构(包括NVIDIA GPU)都支持MAD指令。因此,执行一个MAD的结果是循环次数减少了一半。这种性能的提升并不是没有代价的。一个MAD指令的数据准确性往往比单独的乘法和加法指令的要低。
编译过程中有一些优化标志可以用于控制是否使用这些指令优化
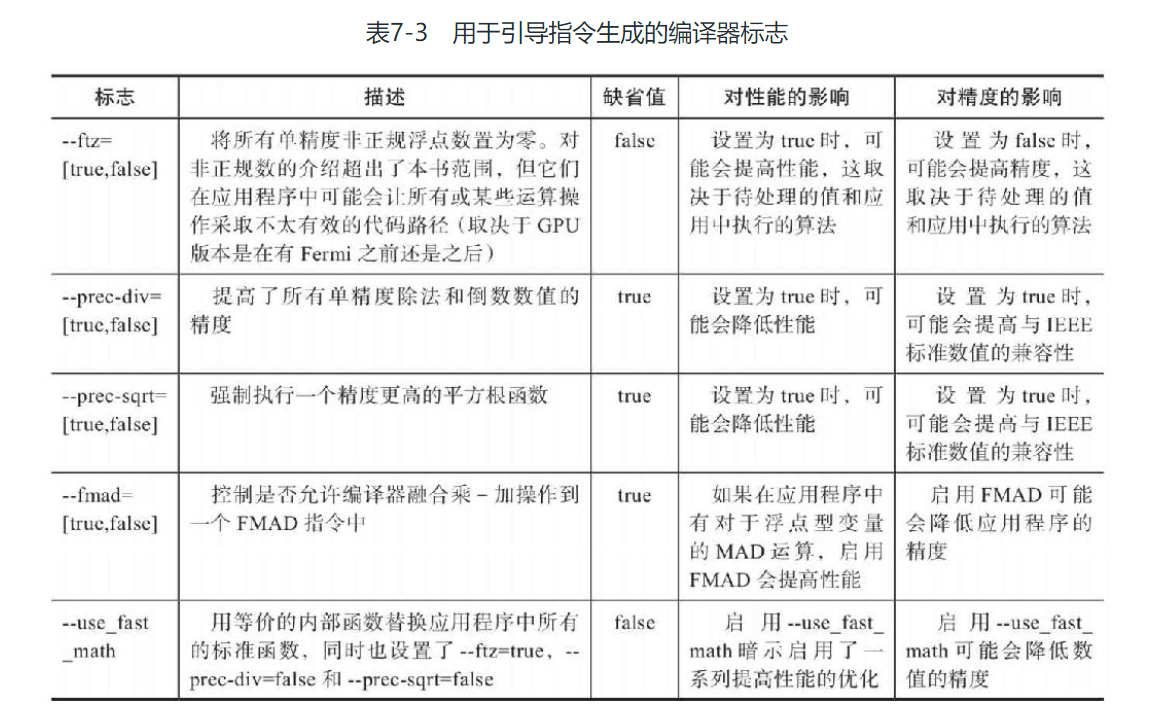
改变这些选项可以使得到的PTX使用不同的指令
-
内部函数和标准函数
CUDA编程第七章: 调整指令级原语_cuda fmad_Janus_V的博客-CSDN博客
CUDA将所有算数函数分成内部函数和标准函数。标准函数用于支持可对主机和设备进行访问并标准化主机和设备的操作,包含来自于C标准数学库的数学运算,如sqrt、exp和sin, 也包括单指令运算如乘法和加法。而CUDA内置函数只能对设备代码进行访问,如果一个函数是内部函数或是内置函数,那么在编译时对它的行为会有特殊响应,从而产生更积极的优化和更专业化的指令生成 如三角函数指令, 很多都是直接在GPU上通过硬件实现的, 执行起来有很高的效率
在CUDA中, 同样存有很多与标准函数功能相同的内部函数, 如:
- 标准函数中的双精度浮点平方根函数也就是
sqrt - 有相同功能的内部函数是
__dsqrt_rn - 还有执行单精度浮点除法运算的内部函数:
__fdividef
内部函数分解成了比与它们等价的标准函数更少的指令,这会导致内部函数比等价的标准函数更快,但数值精确度却更低,因此可以通过精确度考虑选用标准函数还是内部函数。比如对于乘方运算,其内部函数版本只有17条指令:
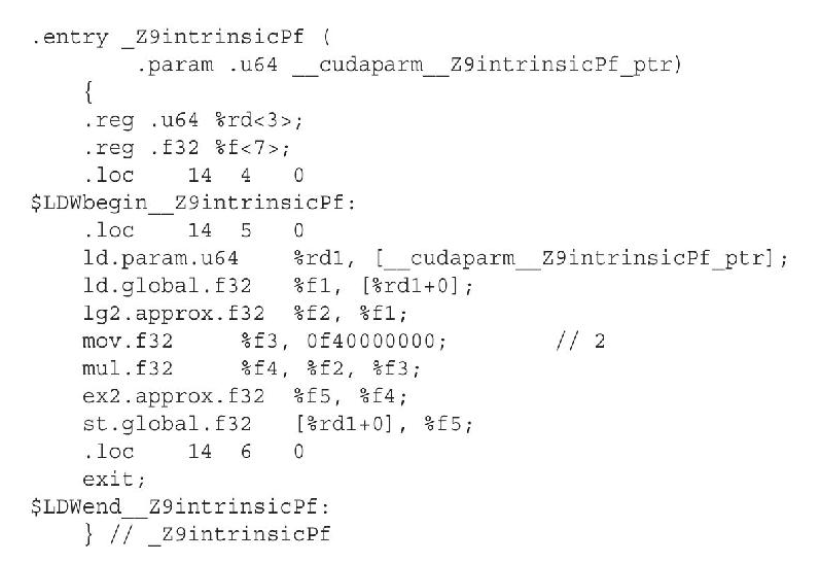
而标准函数有344行代码(CUDA 5.0),使用内部函数相较于标准函数来说,速度提升了将近24倍。
内部函数也有不同的版本,根据后缀区分

内部函数(intrinsic)和标准函数(mathematical function)的列表见 CUDA Math API :: CUDA Toolkit Documentation (nvidia.com)
- 标准函数中的双精度浮点平方根函数也就是
本文作者:thz
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!